This single insight reshapes our understanding of how LLMs evaluate and rank content:
**ChatGPT did not always reference individual pages.
Instead, it sometimes cited the entire domain as if it were an established authority.**
And this happened despite the fact that:
In other words, the model treated a zero-authority domain as if it had domain-level trust.
What This Proves About LLM Ranking Models
From these observations, several critical patterns emerged:
✔ LLMs build domain embeddings extremely early
Even with no off-page signals, the model created a conceptual representation of the domain.
✔ LLMs assign semantic identity based on content quality, not backlinks
The structure and internal consistency of the site were enough to trigger domain-level trust.
✔ LLMs trust semantic structure over historical authority
Entity enrichment, content clustering, consistent formatting, and topical coverage outweighed lack of links.
✔ LLMs rely on the internal content network, not external authority indicators
Cross-linking, consistent headers, and shared entities created a recognizable knowledge graph.
A Behavior Typically Reserved for Industry Giants
This domain-level citation behavior is commonly seen with long-established sites such as:
Moz
BrightLocal
Whitespark
HubSpot
Semrush
These sites have:
Yet our brand-new domain exhibited the same behavior.
⭐ The Most Surprising Outcome
Across multiple LLM platforms, our new domain didn’t just appear —
it often ranked above these established authority sites.
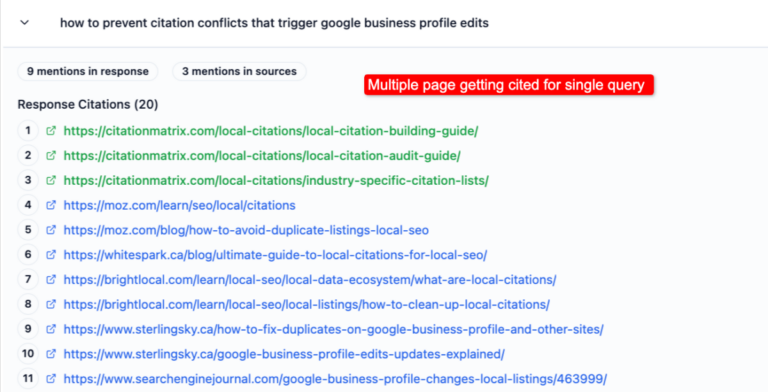
Screenshots show CitationMatrix.com cited:
This is not possible under traditional SEO ranking systems.
It demonstrates a fundamental shift:
Freshness + Topical Coverage > Historical Authority (in LLM ranking)
LLMs prioritized:
Recent, up-to-date content
Dense entity coverage
Deep topical completeness
Semantic clarity and structure
Internal cohesion of the content network
Micro-snippets suitable for extraction
Clean, consistent formatting
These signals outweighed:
Backlinks
Domain age
Domain Rating
Historical trust
Legacy brand power
This finding is transformative for AI SEO:
LLMs reward semantic authority, not link authority.
LLMs reward knowledge structure, not domain history.
Your domain was effectively treated as a topical expert, even in its first few days online.

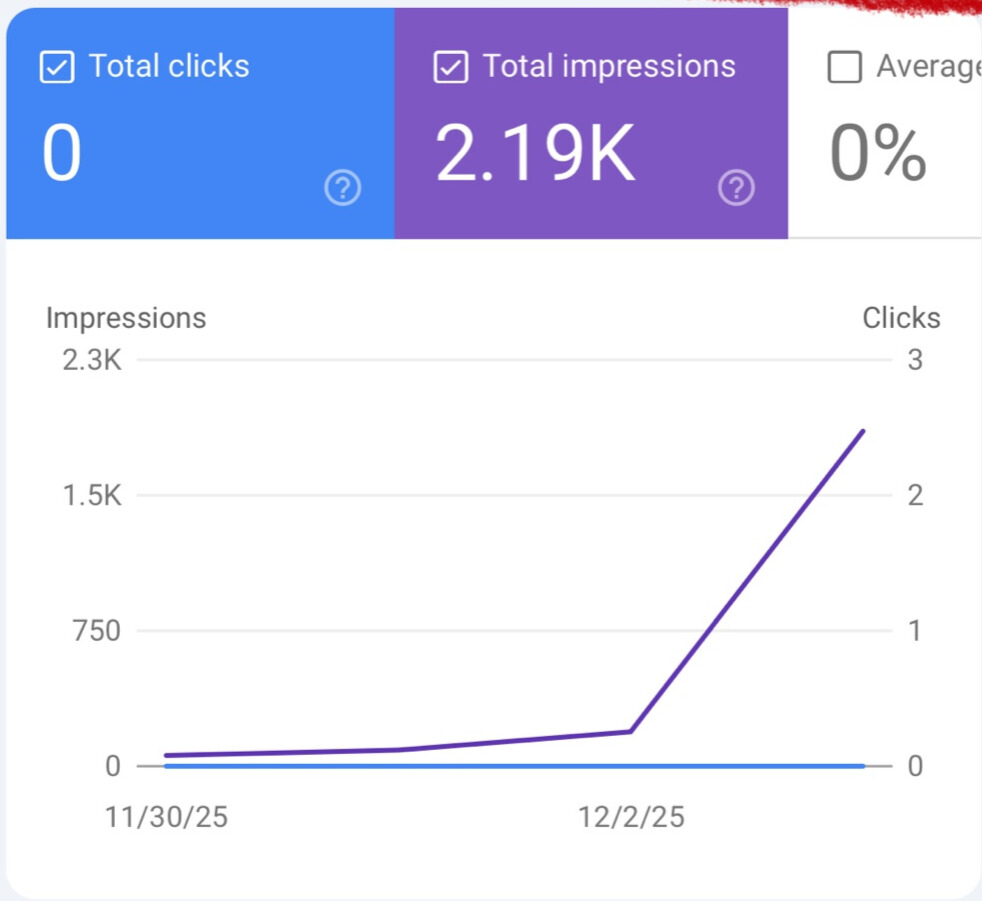


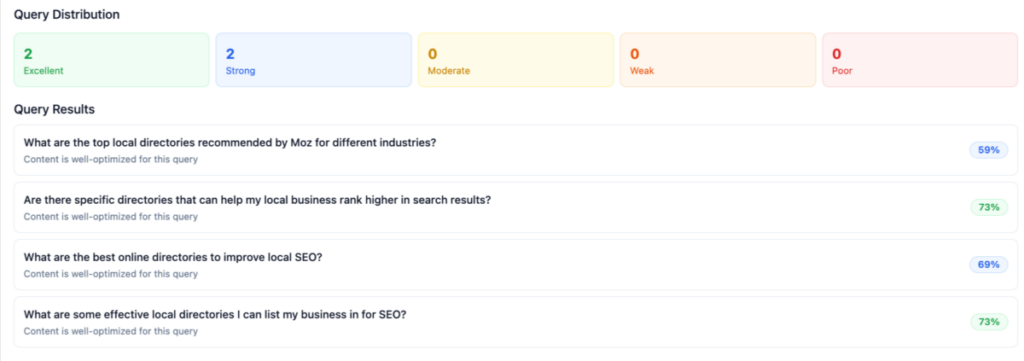

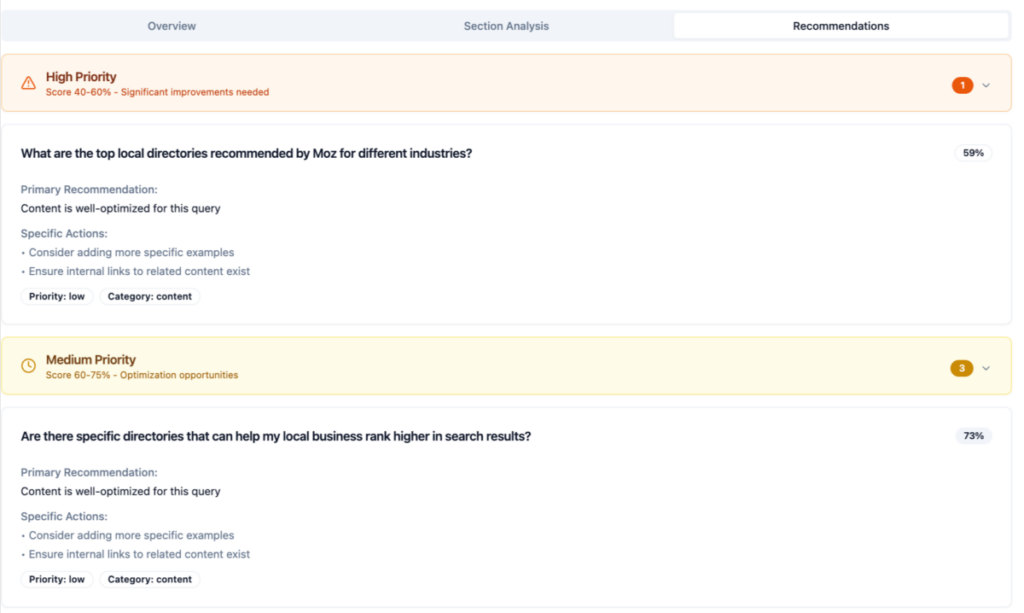

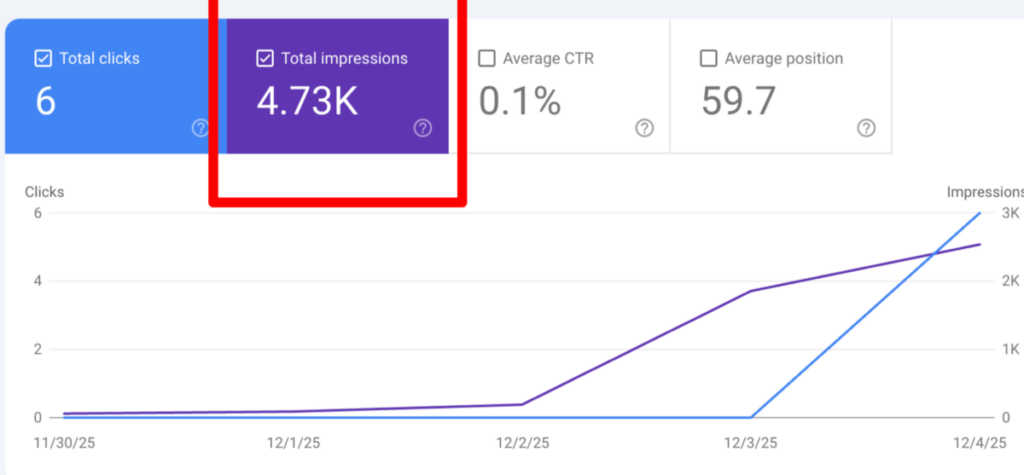
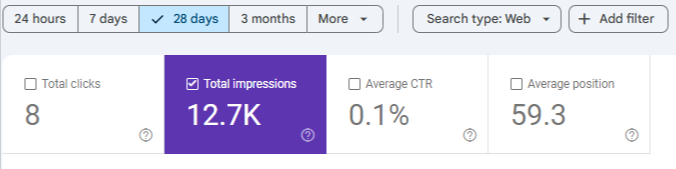
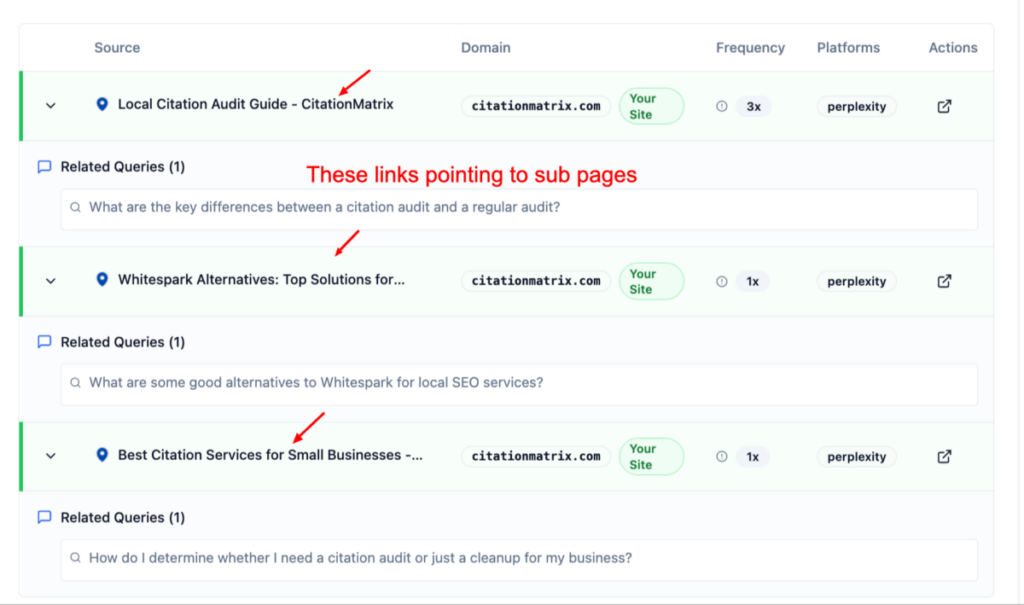
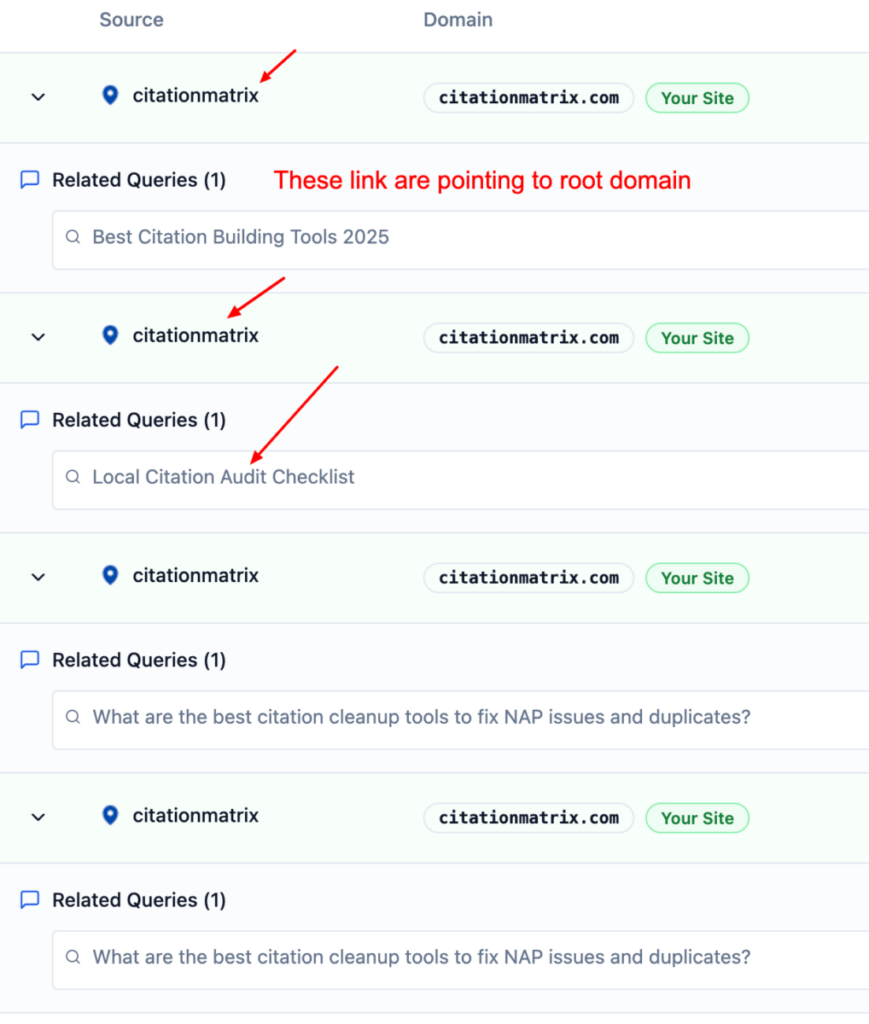
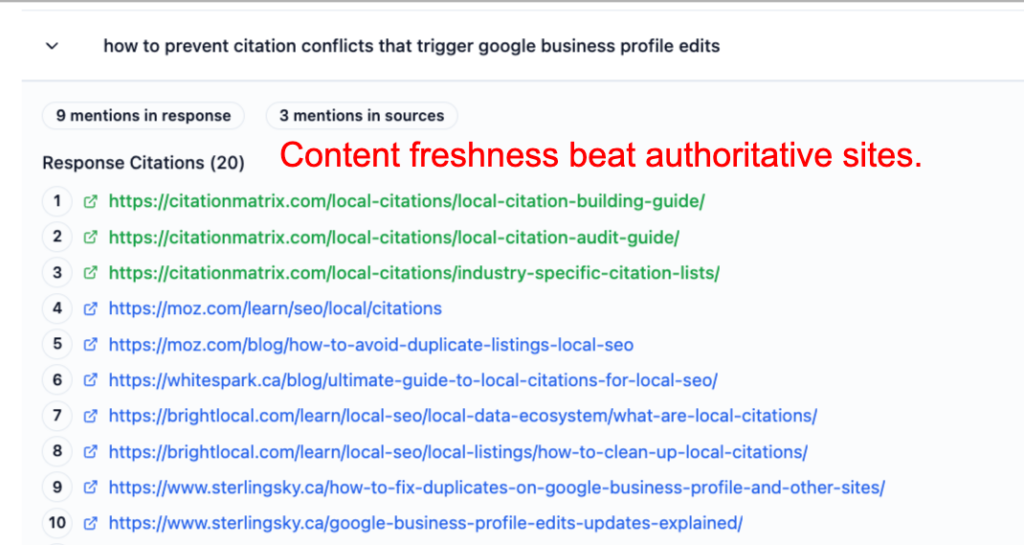
 No, LLMs do NOT require backlinks
No, LLMs do NOT require backlinks Semantic clarity
Semantic clarity
