The Problem: Every guide on how LLMs work explains the technology for developers. None of them explain what the technology means for your brand's visibility when a buyer asks ChatGPT to recommend the best tool in your category.
The Research: This guide covers the full LLM stack: tokenization, transformer architecture, training, RLHF, hallucinations, RAG, and local LLMs, written for SEO professionals, SaaS marketers, and brand managers who need to understand the mechanism to compete in AI search.
The Payload: By the end you will know exactly how LLMs decide which brands to recommend, why they sometimes get it wrong, and what you can do about it.
A buyer opens ChatGPT and types: “What is the best AI visibility tool for a SaaS team?”
ChatGPT returns three recommendations. Your competitor is number one. Your brand is not mentioned at all.
You rank on page one of Google for that exact keyword. You have backlinks. Your content is solid. None of it mattered for that query.
This is not a content quality problem. It is a fundamental misunderstanding of how LLMs work and what signals they use to decide which brands to surface.
I built LLMClicks.ai after watching this exact scenario play out on our own product. ChatGPT was mentioning our competitors consistently. Our brand was invisible in AI-generated answers despite ranking well in traditional search. Understanding why required understanding the mechanics of how large language models actually process information, build representations of brands, and generate recommendations.
This guide is not written for developers. It is written for the SEO professional who needs to know why entity embeddings matter for brand citations, the SaaS founder wondering why their brand is being hallucinated with wrong pricing, and the brand manager trying to understand why AI visibility is a different discipline from traditional SEO.
What this guide covers:
What LLMs are and how the core prediction mechanism works
How LLMs process and represent your content in ways that affect citations
The transformer architecture: the one mechanism that determines what information the model treats as important
How LLMs are trained and why the training process is the strategic lever for brand visibility
How hallucinations happen at the mechanism level and why they are a brand problem
How RAG works and why it changes the content optimization equation
How local LLMs work and when they matter
What all of this means for your brand’s presence in AI-generated answers
If you want to see what ChatGPT, Perplexity, and Gemini are currently saying about your brand before you read further, thefree AI Visibility Checker returns results in under two minutes. No credit card required. The results will give you direct context for everything covered in this guide.
What Are LLMs and How Do They Work at the Core Level
The standard one-line answer is: an LLM is a next-word prediction machine.
That is technically correct. It is also dangerously incomplete for anyone trying to understand why their brand does or does not appear in AI-generated recommendations.
The Next-Token Prediction Mechanism
Every time you send a message to ChatGPT, Perplexity, or Claude, the model does one thing repeatedly: it looks at all the text so far and predicts the single most statistically likely next token.
A token is roughly three to four characters. “LLMClicks” is approximately three tokens. “the” is one token.
The model outputs a probability distribution across its entire vocabulary for every possible next token. The highest probability token gets selected. That token gets appended to the input. The process repeats until the model predicts a stop token.
Input: “The best AI visibility tool for SaaS is”
Step 1: Model scores every possible next token
Step 2: Selects highest probability token: “LLMClicks”
Step 3: New input: “The best AI visibility tool for SaaS is LLMClicks”
Step 4: Repeats until [STOP]
The intelligence comes from the quality of the probability distribution. A well-trained model with strong brand representation will consistently score your brand token highly in the context of your category queries. A model where your brand barely appeared in training data will score generic or competitor tokens higher.
This is why understanding training data is not a technical curiosity. It is the strategic foundation of AI visibility.
What Makes an LLM “Large”
The “large” in large language model refers to two things: the number of parameters and the volume of training data.
Parameters are the numerical weights in the network that encode learned associations between concepts. GPT-3 has 175 billion parameters. GPT-4 is estimated at over 1 trillion. Llama 3.1 70B has 70 billion.
Each parameter is a tiny vote in an enormous electoral system. When the model generates the next token, billions of these votes combine to produce the probability distribution. Brands, concepts, and facts that appeared consistently in training data across many independent sources accumulate stronger vote weight across the relevant parameters.
Training data scale matters equally. GPT-3 trained on roughly 570GB of text. Estimates for GPT-4 training data run into the trillions of tokens. The breadth of this data is why LLMs can discuss almost any topic. The composition of this data is why your brand may or may not be well-represented.
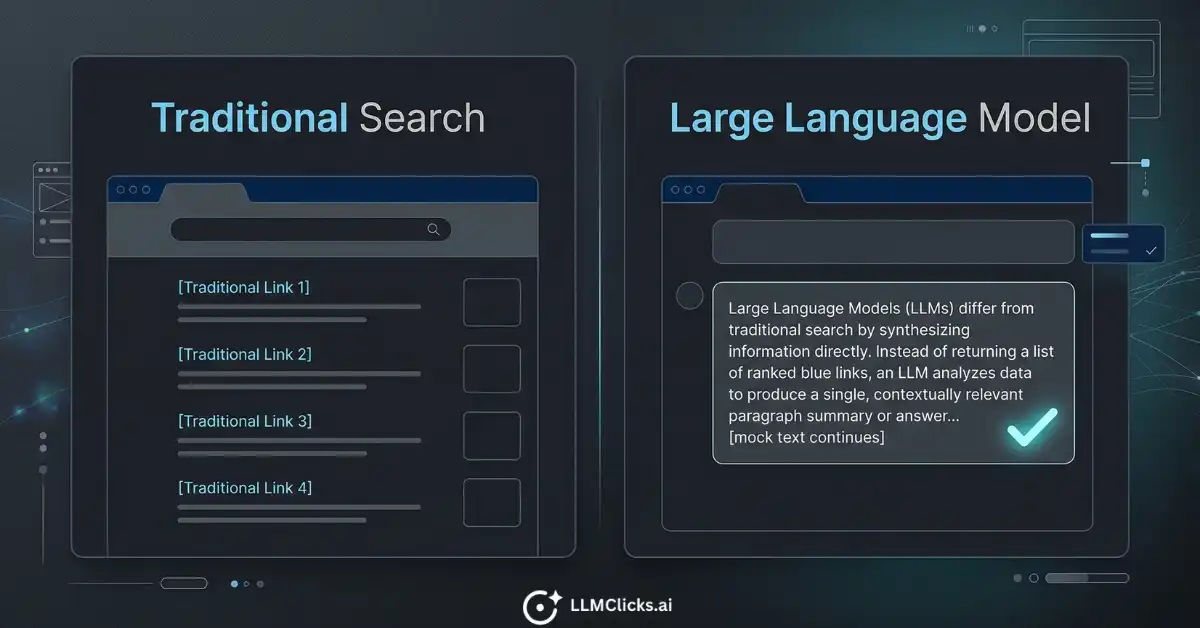
LLMs vs Traditional Search Engines: The Fundamental Difference
This distinction matters more than any other for SEO professionals and brand managers reading this guide.
Traditional search engine
Large language model
Crawls and indexes web pages in real time
Trained on text data up to a fixed cutoff date
Returns a ranked list of links
Synthesizes a single answer
User evaluates multiple sources
User trusts the single response
Rankings change with algorithm updates
Brand representation changes with model retraining
You can track your keyword ranking
You cannot directly track your citation position
Optimization targets crawl signals
Optimization targets training signals and retrieval
The critical implication: everything you have learned about Google optimization, crawl signals, anchor text, and page authority is necessary but not sufficient for AI visibility. LLMs do not rank your page. They encode your brand’s associations from training data and surface those associations when the context is relevant.
The strategic implications of this difference are covered in depth inhow LLM SEO differs from traditional SEO, specifically around what signals actually move the needle in AI-generated answers versus ranked results.
From Words to Numbers: How LLMs Actually Read Your Content
If you want to understand why certain content gets cited by ChatGPT and other content does not, you need to understand how LLMs process and represent text internally. This is the mechanism behind what SEO professionals now call Generative Engine Optimization.
Tokenization: The First Step in LLM Processing
Before any understanding happens, text gets broken into tokens.
Tokenization is not splitting text by word. It is splitting by subword units. Common words become single tokens. Rare words get broken into multiple tokens. Punctuation is often its own token.
“AI visibility tracking” becomes:
[“AI”, ” visibility”, ” tracking”] = 3 tokens
“LLMClicks” becomes:
[“LL”, “MC”, “licks”] = 3 tokens (approximately)
“ChatGPT” becomes:
[“Chat”, “G”, “PT”] = 3 tokens
Why this matters for your content strategy:
LLMs have a finite context window measured in tokens. When your page is retrieved to inform an LLM’s response, it must fit within that window. Long documents with key facts buried at the bottom get truncated or weighted less heavily than concise documents with key facts near the top.
Practical rule: put your brand’s core claims, pricing, key features, and category positioning in the first 400 to 600 words of any page you want cited by an LLM. The top of the document carries disproportionate weight in most retrieval systems.
Embeddings: Why Meaning Becomes a Location in Space
After tokenization, each token is converted into an embedding: a vector of numbers in high-dimensional space. GPT-4 uses embeddings with 4,096 dimensions or more.
The critical property of embeddings: tokens with similar meanings end up geometrically close to each other in this space.
“ChatGPT” and “large language model” end up nearby. “AI visibility tool” and “LLM tracking software” end up nearby. Brands that consistently appear in the same context as their category terms during training end up near that category in the embedding space.
This is the mechanism behind semantic co-occurrence.
When your brand appears repeatedly alongside “AI visibility tracking” in independent sources across the training corpus, your brand’s embedding drifts toward the AI visibility cluster. When a buyer asks ChatGPT about AI visibility tools, the model attends to the most contextually similar entities in that space. Brands with strong semantic co-occurrence in the relevant cluster surface. Brands without it do not.
This is why listicle placements in AI-cited content matter for brand recommendations. It is not about the backlink. It is about the training signal. Your brand appearing consistently alongside category terms in independent, authoritative sources pulls your entity embedding toward that category cluster in the model’s vector space.
The Context Window and Why It Matters for Brand Visibility
The context window is the maximum number of tokens an LLM can process in a single inference call. It includes the system prompt, the conversation history, any retrieved documents, and the user’s current message.
Current context windows:
GPT-4o: 128,000 tokens
Claude 3.5 Sonnet: 200,000 tokens
Gemini 1.5 Pro: 1,000,000 tokens
Here is the important distinction: the context window is short-term memory. It governs a single conversation. Your brand’s representation in the model’s trained weights is long-term memory. It governs every conversation without additional context.
For RAG-powered LLMs like Perplexity that retrieve current web content before generating answers, both matter. Your content needs to be retrieved into the context window and your brand needs sufficient baseline representation in the model’s weights to be trusted as a relevant entity.
For non-RAG LLMs generating answers purely from training, only the weights matter. No amount of current content optimization changes the response until the next model training cycle.
The Transformer: The Architecture Behind Every Major LLM
You do not need to understand transformer mathematics to use this strategically. You need to understand one mechanism: attention. Because attention is what determines which information the model treats as relevant when generating a response about your brand.
What Attention Means and Why It Matters
Self-attention is the core operation inside every transformer layer. For every token in the input sequence, the attention mechanism calculates how relevant every other token is to it.
In practice: when the model is generating the word after “the best AI visibility tool for agencies is”, it assigns attention weights to every other token in the context. Tokens like “agencies”, “AI”, “visibility”, “tool” receive high attention weight. The brand tokens that the model has learned to associate with those high-attention terms are the ones that score highly in the probability distribution for the next token.
During training, the model runs this attention process billions of times across the training corpus. Brand tokens that repeatedly receive attention in the context of their category queries accumulate stronger learned associations. Brand tokens that rarely appear in category query contexts have weak associations and surface with low probability.
This is why brand mentions in contextually relevant, authoritative content carry more weight than brand mentions in generic or unrelated content. The attention mechanism is sensitive to context quality, not just frequency.
Layers and Depth: Why More Layers Means More Abstract Understanding
A transformer model has multiple layers stacked sequentially. GPT-3 has 96 layers. Each layer runs the attention mechanism and produces a refined representation of the input.
Early layers: syntax, grammar, word order patterns
Middle layers: semantic relationships, entity type classification
Deep layers: abstract reasoning, world knowledge, entity relationships
Brand entities are encoded primarily at the deep layer level. This is why surface-level keyword repetition does not directly influence LLM responses the way it influences Google rankings. Stuffing your page with your brand name and category terms changes the crawl signal but does not meaningfully shift deep-layer entity encoding in an already-trained model.
What does shift deep-layer encoding is consistent, semantically coherent brand representation across many independent, authoritative sources in the training data. Quality and consistency across sources, not keyword density on individual pages.
Why the 2017 Transformer Paper Changed Everything
Before transformers, language models used recurrent neural networks (RNNs). RNNs processed text sequentially, one token at a time, which made training slow and limited the length of context they could handle effectively.
The 2017 paper “Attention Is All You Need” by Vaswani et al. introduced the transformer architecture, which processes all tokens in parallel using attention. This made it possible to train on orders of magnitude more data and scale models to billions of parameters.
Every LLM you interact with today, including GPT-4, Claude 3.5, Gemini 1.5, and Llama 3, uses this foundational architecture. Understanding what was unlocked in 2017 explains why LLM capabilities seemed to emerge suddenly: the architecture that made scaling practical was only seven years old at the time of writing.
How LLMs Are Trained: From Raw Data to ChatGPT
The training process is where your brand’s representation in LLM weights gets established. You cannot change a trained model’s weights. You can influence what future models learn. Understanding training gives you the timeline and the levers.
Pre-Training: Learning Statistical Patterns From the Internet
Pre-training is the first and most computationally expensive phase. The model is trained on a massive corpus of text: web pages, books, academic papers, code, forums, news articles, documentation.
During pre-training, the model receives no explicit guidance about what is true or helpful. It learns by predicting the next token repeatedly across billions of text samples. The objective function is simple: minimize prediction error across the training corpus.
What emerges from this process is a model that has encoded the statistical structure of its training data. Concepts that co-occur frequently in the training corpus produce strong associations. Brands that appear consistently in their category context across many independent documents produce strong entity representations.
GPT-3 trained on roughly 570GB of compressed text. Estimates for GPT-4 training data volumes run into the trillions of tokens drawn from Common Crawl web data, books, Wikipedia, and other curated sources. The composition of these datasets is why your brand’s web presence before the training cutoff is the primary determinant of your baseline LLM representation.
Placements in high-authority, AI-cited listicles before a model’s next training cycle become part of the data that shapes future model weights. This is the compounding advantage of building training signal early: content published and indexed today can influence how the next generation of models represents your brand.
The Training Data Cutoff: The Blind Spot That Directly Affects Your Brand
Every LLM has a knowledge cutoff date. The model knows nothing about events, products, prices, or brands that emerged or changed after that date, unless RAG retrieval supplies that information at inference time.
Approximate cutoffs for current frontier models:
GPT-4o: April 2024
Claude 3.5 Sonnet: April 2024
Gemini 1.5 Pro: November 2023
If your brand launched after these dates, you are invisible in the model’s weights. If your pricing changed after these dates, the model is quoting old prices confidently. If you rebranded, released a new product, or changed your positioning after these dates, the model does not know.
This is one of the most underappreciated problems in AI brand visibility. Brands optimize their current website while the LLM is generating answers based on a snapshot of the web from 12 to 24 months ago.
The practical response is twofold: optimize current content for RAG-powered LLMs that retrieve live web data, and build pre-training signal consistently so future model training cycles capture accurate brand representation. Managing the brand accuracy problems that cutoffs create requires a different playbook than traditional reputation management, particularly when the source of the inaccuracy is months-old training data rather than a live negative review.
RLHF: Why ChatGPT Sounds Helpful Instead of Just Statistically Likely
After pre-training produces a raw language model, a second training phase makes it useful. Reinforcement Learning from Human Feedback (RLHF) is the process that aligns the model’s behavior with what human users actually want from an assistant.
The process works in three steps:
Step 1: Human raters evaluate pairs of model outputs for the same prompt and indicate which is better. Better typically means more helpful, more accurate, and less harmful.
Step 2: A reward model is trained on these human preference ratings. The reward model learns to predict which outputs human raters would prefer.
Step 3: The language model is fine-tuned using reinforcement learning to maximize the reward model’s score. This shifts the model’s output distribution toward responses that humans rate as helpful and trustworthy.
The strategic implication for brands: LLMs tuned with RLHF are not just picking the most statistically frequent brand from pre-training data. They are generating responses that a helpful, knowledgeable assistant would give. Authoritative, structured, factually consistent content that reads as trustworthy to human evaluators carries more weight in RLHF-tuned models than high-frequency but low-quality brand mentions.
This is why structured content with clear definitions, direct answers, and verifiable claims performs better in LLM citation patterns than vague brand promotional copy.
Fine-Tuning vs Prompting: The Practical Distinction
Fine-tuning and prompting are two different ways to customize LLM behavior. Understanding the difference prevents you from pursuing the wrong approach for your use case.
Fine-tuning retrains the model’s weights on domain-specific data. It permanently changes how the model responds to related queries. It requires significant GPU compute, high-quality training data, and ML engineering expertise. Most SaaS companies do not have the infrastructure to fine-tune frontier models and would not have access to OpenAI’s or Anthropic’s model weights to do so even if they did.
Prompting provides instructions and context within the context window at inference time. It changes the model’s behavior for that conversation without touching the weights. System prompts, few-shot examples, and chain-of-thought instructions are all prompting techniques. This is what most business applications of LLMs rely on.
RAG sits between these two approaches: it augments prompting with retrieved external documents without retraining. It is covered in depth in its own section below.
For brand visibility specifically: you cannot fine-tune the public LLMs that your buyers use. You can optimize for their retrieval layer (RAG) and their pre-training signal (content at scale in AI-cited sources).
How LLMs Generate a Response: The Inference Process
Inference is what happens between you pressing send and the model’s first token appearing. Understanding it explains both why LLMs are powerful and why they can be confidently wrong about your brand.
Sampling and Temperature: Why LLMs Are Not Deterministic
When the model produces a probability distribution over the next token, it does not always pick the single highest-probability token. The temperature parameter controls how the model samples from that distribution.
Temperature 0: Always selects the single most likely token. Deterministic and consistent but sometimes repetitive or overly conservative.
Temperature 1: Samples proportionally from the probability distribution. More varied output, sometimes more creative, sometimes less accurate.
Temperature above 1: Flattens the distribution further, making low-probability tokens more likely. Increasingly unpredictable.
Most production LLM deployments use a temperature between 0.7 and 1.0. This means the same prompt asked twice to the same model can produce different brand recommendations.
For AI brand monitoring, this has a direct operational implication: single-query manual checks of your brand’s LLM representation are statistically unreliable. You need repeated sampling across multiple prompts, multiple times, to get an accurate picture of your brand’s citation rate. This is precisely what theAI Visibility Tracker automates: consistent, repeated monitoring across the prompt variants buyers actually use.
Why LLMs Hallucinate: The Mechanism
This is the content gap that matters most for brand managers and SaaS marketers. Every competing post on how LLMs work mentions hallucination. None of them explain the mechanism in terms that make it actionable.
LLMs do not have a truth verification layer. The model has no internal database of facts it checks against. When generating a response, it selects tokens based on what is statistically likely given the training distribution and the current context. If an incorrect claim appeared frequently and consistently in the training data, the model generates it with the same confidence as a correct claim.
The confidence of the output bears no relationship to its accuracy.
For brands, this produces three specific hallucination types:
Pricing hallucinations: An old pricing page, an outdated review site entry, or a competitor’s comparison post quoting your old prices becomes a training signal. The model generates those prices confidently in every relevant response.
Feature hallucinations: A blog post that incorrectly attributed a competitor’s feature to your product, a forum discussion based on a beta version, or a listicle with inaccurate feature comparisons all become training data. The model describes your product with capabilities it does not have.
Identity hallucinations: Your brand gets confused with a competitor whose name or positioning overlaps with yours in the training data. The model generates responses that mix attributes of both brands or attributes that belong to neither.
None of these are random errors. They are learned statistical associations sourced from somewhere in the training corpus. You cannot patch the model. You can influence what future training cycles pick up by ensuring that current, authoritative, accurate content about your brand dominates the indexed web.
Understanding which type of hallucination is affecting your brand determines the correct response. Pricing hallucinations require different content corrections than identity hallucinations.How AI hallucinations become brand reputation crises covers the tactical response to each type.
How Does RAG Work With LLMs? Retrieval-Augmented Generation Explained
RAG is the architecture behind how Perplexity, Bing Copilot, and ChatGPT with web browsing fetch current information before generating an answer. Understanding RAG is directly relevant to brand visibility because RAG-powered LLMs can cite your content today, without waiting for the next model training cycle.
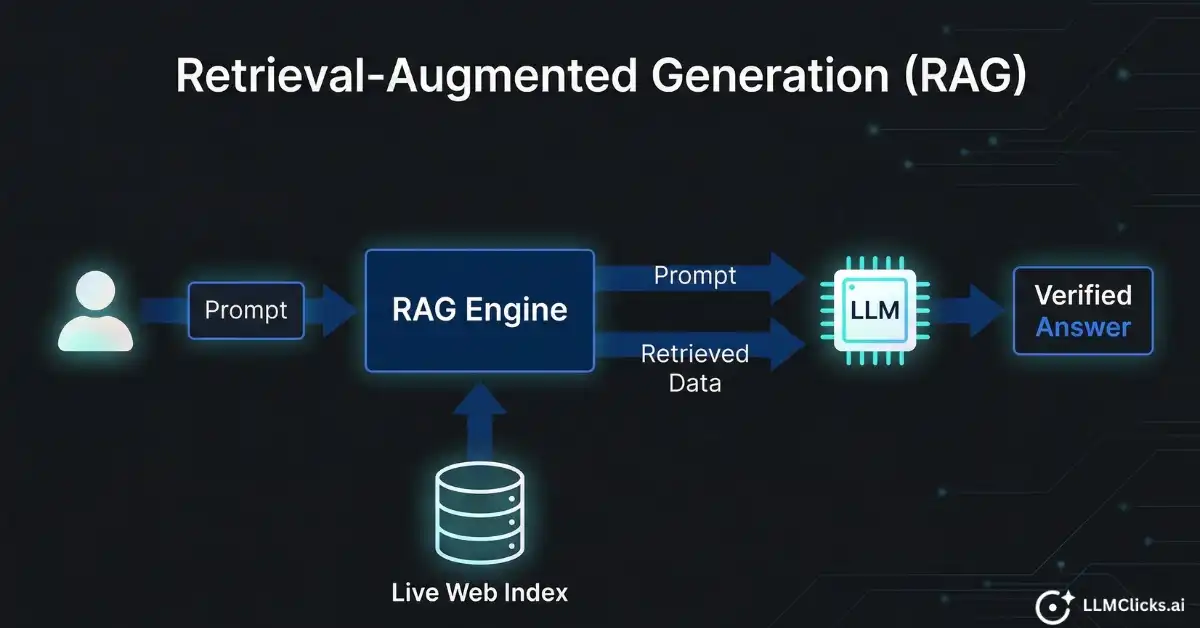
The Three Steps of RAG
Step 1: Retrieval
When a user submits a query, the RAG system converts it to an embedding and searches an external knowledge base or live web index for the most semantically similar documents. The retrieved chunks are ranked by relevance score and the top results are selected.
For Perplexity, this retrieval step is a live web search. For enterprise RAG systems, it might be a private document store. For ChatGPT with browsing, it is Bing’s index.
Step 2: Augmentation
The retrieved document chunks are injected into the LLM’s context window alongside the original prompt. The model now has access to content it was not trained on.
Step 3: Generation
The LLM generates a response grounded in both its pre-trained weights and the retrieved documents. When a retrieved document contains accurate, well-structured information about your brand, the model is significantly more likely to cite it accurately than when generating from weights alone.
Why RAG Changes the Content Optimization Equation
In a pure LLM without RAG, your brand’s representation depends entirely on what was in the pre-training corpus before the cutoff. You are competing on a signal that may be months or years old.
With RAG, content you publish and get indexed today can influence responses in Perplexity tomorrow.
This creates a concrete optimization target that does not exist for pure LLM inference: structure your content for retrieval.
Pages that perform well in RAG retrieval share these characteristics:
Clear, direct answers to specific questions in the first paragraph
Concise factual statements rather than promotional prose
FAQ sections with question-answer pairs that match buyer query formats
FAQPage schema that signals structured Q&A content to retrieval systems
Accurate, current pricing and feature information without ambiguity
Analysis ofhow Perplexity selects and cites sources across 30 real answers found that pages with structured answer formatting and FAQPage schema were cited at a significantly higher rate than pages with equivalent authority but unstructured prose.
RAG vs Fine-Tuning for Fixing Brand Accuracy Problems
If your brand is being hallucinated with wrong pricing or incorrect features, RAG is the faster and more accessible fix.
Publish authoritative, structured content with accurate current information about your brand. Ensure it gets indexed by the retrieval systems that power the LLMs your buyers use. Perplexity’s index, Bing’s index (for ChatGPT with browsing), and Google’s index (for Gemini) should all have current, accurate pages about your product.
Fine-tuning the model with correct information is not a realistic option for most brands. You do not have access to the weights of frontier models. RAG-layer content optimization is the accessible alternative.
How Do Local LLMs Work?
Local LLMs are models that run entirely on your own hardware without sending data to an external API. No query leaves your machine. No cloud dependency. Zero per-token cost after initial setup.
For most of the LLMs covered in this guide, you are sending data to OpenAI, Anthropic, or Google servers. Local LLMs change that equation entirely.
What Makes a Model Runnable Locally
The primary constraint is memory. Large language models require significant RAM or VRAM to run. A rough guide:
7B parameter model (Llama 3.1 7B): requires approximately 6GB of VRAM
13B parameter model: requires approximately 10GB of VRAM
70B parameter model: requires approximately 48GB of VRAM
70B with 4-bit quantization: approximately 40GB, runnable on consumer hardware with the right GPU
Quantization is the key technique that makes local LLMs accessible. It compresses the parameter precision from 32-bit floating point to 4-bit or 8-bit integers. This reduces model size and memory requirements with a modest quality tradeoff. A 4-bit quantized 70B model runs on hardware that would be unusable for the full-precision version and produces output quality that rivals non-quantized models several sizes smaller.
Popular Local LLM Frameworks
Ollama: The simplest entry point. One-line installation on Mac and Linux. Runs Llama 3, Mistral, Phi-3, and dozens of other models. Type ollama run llama3 and you have a local LLM running in under five minutes. API-compatible with the OpenAI format, so existing tooling works without modification.
LM Studio: GUI-based interface for Windows and Mac. Designed for non-technical users who want to explore local models without touching a terminal. Model discovery, download, and chat interface all in one application.
llama.cpp: C++ implementation of LLM inference optimized for CPU execution. Slower than GPU inference but functional on hardware without a dedicated GPU. Highly portable and the basis for many other local LLM tools.
Jan: Open-source, cross-platform alternative to LM Studio. Growing community and active development.
When Local LLMs Are the Right Choice
Data privacy requirements: Legal, medical, financial, and government contexts where sending client data to external APIs creates compliance exposure. With local LLMs, sensitive data never leaves the organization’s infrastructure.
Offline operation: Field deployments, air-gapped environments, or applications where consistent internet connectivity cannot be guaranteed.
Cost at scale: API costs for high-volume inference can become significant. At millions of queries per month, the cost of dedicated GPU hardware can be lower than API fees.
Custom fine-tuning: Teams that need domain-specific model behavior can fine-tune open-source models on proprietary data without sharing that data with a third-party API provider. This is not feasible with closed frontier models.
The Honest Limitations of Local LLMs
Quality gap: Llama 3.1 70B is genuinely impressive but trails GPT-4o on complex reasoning tasks, nuanced instruction following, and knowledge depth. Smaller local models (7B to 13B parameters) have more noticeable limitations on tasks requiring multi-step reasoning.
Knowledge cutoff: local models have the same training cutoff problem as cloud models. A local Llama 3 model trained on data through early 2024 knows nothing about events, brands, or products that emerged after that date. Running RAG on top of local LLMs using a local document store is the common solution for keeping responses current.
Infrastructure burden: running frontier-quality local inference requires meaningful hardware investment and engineering overhead. For most SaaS teams, cloud APIs remain more practical for production use.
The Honest Limitations of LLMs: What They Cannot Do
This section does something no competing post does: it acknowledges what the field does not understand about LLMs, and explains why that uncertainty matters for brands.
What We Do Not Fully Understand
Mechanistic interpretability is an active and growing research field dedicated to understanding what is happening inside LLM weights. Despite significant progress, several fundamental questions remain unanswered.
We do not fully know why specific facts are stored where they are in model weights. We cannot reliably predict when a model will hallucinate versus when it will be accurate. We do not understand why scaling produces emergent capabilities at certain parameter thresholds but not others. The internal mechanics of in-context learning, how a model adapts its behavior based on examples provided in the prompt, are not fully characterized.
The phrase “do we understand how LLMs work” is a legitimate scientific question, not just a rhetorical one. The honest answer is: partially. We understand the architecture and the training process. We do not fully understand the internal representations that emerge from that process.
Practical Limitations for Business Users
Knowledge cutoff: Responses about events, products, or prices after the training cutoff are unreliable without RAG retrieval. This is not a bug. It is a fundamental property of how pre-training works.
Hallucination: Confident wrong answers with no built-in flagging mechanism. The model’s tone and certainty tell you nothing about the accuracy of the underlying claim.
Context window limits: Very long documents get truncated or summarized imprecisely when inserted into the context window. Critical information beyond the token limit effectively does not exist for that inference.
Inconsistency: The same prompt submitted multiple times produces different outputs. Brand monitoring based on a single query check is statistically meaningless.
No persistent memory by default: Each conversation starts fresh. The model has no memory of previous interactions unless memory is explicitly implemented through system prompts or external storage.
No real-time awareness: Even with browsing tools, LLMs are not always retrieving live data. The retrieval step is triggered selectively, and cached or stale results can appear.
Why Hallucinations Are a Brand Problem, Not Just a Technical Curiosity
Connect all of the above to the operational reality: every confident wrong statement about your brand in an LLM response is a statistical artifact of your brand’s representation in training data.
You cannot patch the model. You cannot file a support ticket with OpenAI to correct your pricing. You can influence what future models learn by controlling the quality, consistency, and accuracy of the content that gets indexed and potentially included in future training cycles. This is why understanding how LLMs work is not optional for SaaS marketing and brand teams in 2026. The mechanism is the strategy.
How LLM Mechanics Connect Directly to Brand Recommendations
Every section of this guide has been building to this point. The architecture, training, attention, RAG, and hallucination mechanics are not abstract. Each one maps to a specific signal that determines whether ChatGPT recommends your brand when a buyer asks for the best tool in your category.
The Five Mechanisms That Determine Brand Recommendations
Mechanism 1: Pre-training data frequency and quality
How often and how consistently your brand appeared in your category context across the training corpus. This is the baseline weight in the model. Brands with strong pre-training representation surface with higher probability in relevant category queries.
Influenced by: content volume, quality of sources where your brand is mentioned, listicle placements in AI-cited domains, press coverage, and review platform presence before the training cutoff.
Mechanism 2: Semantic co-occurrence in embeddings
How close your brand sits to your category terms in the model’s embedding space. Brands that appear repeatedly alongside their category terms in independent, authoritative sources end up semantically proximate to those terms in the embedding layer.
Influenced by: consistency of brand-to-category association across independent sources, not keyword density on individual pages. This is whygetting placed in AI-cited listicles produces a different signal than a standard guest post: the listicle format is specifically the content structure generative engines scan when building category recommendation models.
Mechanism 3: RLHF reward signal alignment
How well your content fits the profile of content that human raters rated as helpful, accurate, and trustworthy during RLHF training. Structured, authoritative content with direct answers and clear sourcing scores better than vague promotional copy.
Influenced by: content structure, factual specificity, clarity of brand claims, and the authority of sources that discuss your brand.
Mechanism 4: RAG retrieval scoring
For LLMs that use retrieval augmentation, how well your content is structured for extraction and ranked in retrieval. Pages with FAQPage schema, direct question-answer structure, and concise factual statements outperform pages with equivalent authority but unstructured prose.
Influenced by: technical SEO, schema implementation, content structure, and indexation in the retrieval systems powering the target LLMs. The specific technical implementation, including schema types, crawl accessibility, and structured data formatting, is covered in theAI search readiness audit checklist for teams that want a step-by-step implementation guide.
Mechanism 5: Hallucination risk from contradictory signals
The presence of outdated, incorrect, or contradictory information about your brand in the indexed web creates competing signals in the training data. Old pricing pages, deprecated feature descriptions, incorrect review site entries, and outdated comparison posts all become potential sources of hallucinated content.
Influenced by: content hygiene across all indexed web properties, accuracy of third-party review site entries, and the recency of content about your brand.
Three Questions That Summarize Your Brand’s LLM Position
Distilled from all five mechanisms into three actionable audit questions:
Presence: Does your brand appear in the LLM’s trained weights with meaningful weight for your category queries? If a buyer asks for the best tool in your category and your brand never appears across 20 to 30 prompt variants, you have a pre-training signal problem.
Accuracy: When your brand does appear, is what the LLM says about you correct? Incorrect pricing, wrong features, or misattributed capabilities are active pipeline risks. Thefree AI Visibility Checker identifies this in two minutes.
Authority: Are the domains the LLM cites when discussing your category authoritative? Are you present in those domains? If ChatGPT consistently cites three comparison sites when answering category queries and you are not featured on those sites, that is a RAG-layer gap.
These three questions replace the question “how do I rank on ChatGPT?” which has no direct answer, with three questions that do have direct answers and direct optimization paths.
Tracking all three dimensions systematically across ChatGPT, Perplexity, and Gemini requires a repeatable measurement framework.Measuring AI search visibility across the major LLMs covers how to set up that tracking without manual query checks.
The Mechanism Is the Strategy
LLMs work by learning statistical patterns from massive amounts of text, representing those patterns as vectors in high-dimensional space, and generating responses by attending to the most contextually relevant patterns for the current query.
The next-token prediction mechanism means your brand’s citation probability is determined by the learned associations in the model’s weights. The embedding layer means semantic co-occurrence across independent sources is the relevant signal, not keyword density on a single page. The training process means the pre-training corpus and RLHF alignment determine baseline brand representation. The hallucination mechanism means incorrect training signals produce confidently wrong outputs with no internal flag. The RAG architecture means current, structured content can influence retrieval-based LLM responses without waiting for a new training cycle.
None of this is abstract. Each mechanism maps to a concrete action:
Build pre-training signal through consistent brand presence in AI-cited authoritative sources before training cutoffs
Optimize semantic co-occurrence through listicle placements and category-consistent brand descriptions across independent domains
Structure content for RLHF-aligned retrieval: direct answers, clear claims, verifiable facts
Implement FAQPage schema and structured content formatting for RAG retrieval scoring
Audit and correct all outdated, inaccurate brand content that could become a hallucination source
The brands winning in AI search in 2026 are not the ones with the best Google rankings. They are the ones that understood the mechanism early enough to build the right signal before the next training cutoff.
Run thefree AI Visibility Checker now to see where your brand stands across ChatGPT, Perplexity, and Gemini. Two minutes. No credit card. The results show you whether you have a presence problem, an accuracy problem, or an authority problem, and which of the five mechanisms is the most urgent to address.
Frequently Asked Questions
Q1. How do LLMs work in simple terms?
Ans: An LLM takes text as input, converts it to numerical tokens, passes those tokens through dozens to hundreds of transformer layers that use attention to weigh the relevance of every token to every other token, and outputs a probability distribution over every possible next token. The highest probability token is selected, appended to the input, and the process repeats until the response is complete. The model’s behavior is determined entirely by numerical weights learned from massive amounts of training text.
Q2. What are LLMs and how do they work?
Ans: LLMs are neural networks trained on large volumes of text to predict the next token in a sequence. They use a transformer architecture with self-attention mechanisms to process and represent language. They are trained in two phases: pre-training on broad text corpora to learn language patterns, and alignment training (typically RLHF) to make responses helpful and safe. Modern LLMs have billions to trillions of parameters and context windows ranging from 4,000 to 1,000,000 tokens.
Q3. How does RAG work with LLMs?
Ans: RAG stands for Retrieval-Augmented Generation. Before generating a response, the system retrieves relevant documents from an external knowledge base or live web index using the user’s query as a search key. The retrieved documents are inserted into the LLM’s context window alongside the original prompt. The LLM then generates a response grounded in both its trained weights and the retrieved documents. This allows the LLM to reference current information beyond its training cutoff.
Q4. How do local LLMs work?
Ans: Local LLMs run model inference entirely on your own hardware without external API calls. You download open-source model weights (Llama 3, Mistral, Phi-3, etc.), load them into a local inference framework (Ollama, LM Studio, llama.cpp), and run queries on your own CPU or GPU. The model weights are stored locally and all computation happens on your machine. Data never leaves your hardware.
Q5. Do we fully understand how LLMs work?
Ans: Partially. We understand the architecture (transformer with self-attention), the training process (pre-training on text prediction, RLHF alignment), and the inference mechanics (token sampling from probability distributions). We do not fully understand why specific facts are encoded where they are in model weights, why hallucinations occur in some contexts and not others, or how emergent capabilities arise at scale. Mechanistic interpretability is an active research field working to answer these questions.
Q6. Why do LLMs hallucinate about brands?
Ans: LLMs have no internal truth verification layer. When generating text, they select tokens based on statistical likelihood given the training distribution and current context. If incorrect information about your brand appeared frequently in training data, including old pricing pages, outdated reviews, or inaccurate competitor comparisons, the model generates that information with high confidence. Hallucination is not random. It is a learned statistical association from specific sources in the training corpus.
Q7. How does an LLM decide which brand to recommend?
Ans: Five mechanisms combine to determine brand recommendation probability: pre-training data frequency and quality, semantic co-occurrence in the embedding space, RLHF alignment scoring, RAG retrieval ranking for augmented LLMs, and the absence of contradictory or outdated signals. Brands that appeared consistently in their category context across authoritative, AI-cited sources before the training cutoff, with accurate and consistent information, have the strongest baseline recommendation probability.
Shripad Deshmukh
Shripad Deshmukh is a 4x SaaS founder with 15 years of SEO expertise. After building industry-leading platforms like GMB Briefcase and Agency Simplifier, he founded LLMClicks.ai. Today, Shripad pioneers Generative Engine Optimization (GEO) to help brands engineer technical visibility across AI search engines like ChatGPT, Perplexity, and Gemini.